Book Recommender System
By Komal Diwe
A book recommender system is a tool that helps users discover new books to read based on their reading preferences. It works by analyzing users’ reading behavior and recommending books similar to those they have read in the past.
Imagine you have just finished reading a book, and you’re looking for your next read. You go to your favorite online bookstore and start browsing, but there are so many options, and you’re not sure what to pick. This is where a book recommender system comes in. It uses your past reading history, preferences, and other data to recommend books that are similar to the ones you have already read and enjoyed.
For example, let’s say you’ve just finished reading “Pride and Prejudice” by Jane Austen. A book recommender system would analyze your reading history and see that you’ve read several other novels by Austen, such as “Emma” and “Sense and Sensibility.” It would then recommend other classic novels by female authors, such as “The Bronte Sisters” or “Jane Eyre” by Charlotte Bronte.
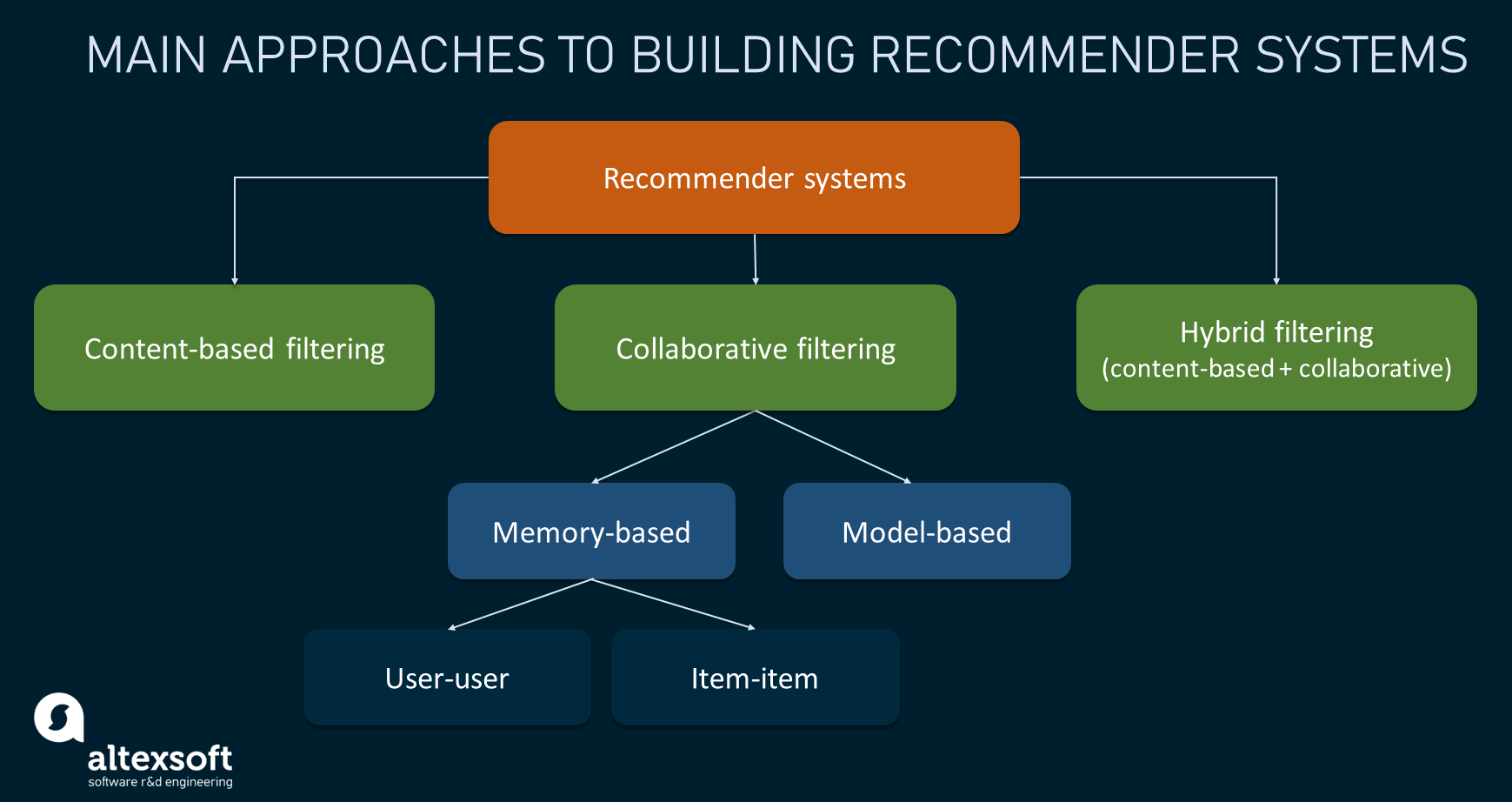
The book recommender system uses various techniques to make these recommendations, such as collaborative filtering, content-based filtering, and hybrid methods. Collaborative filtering is based on the idea that if a user A likes item 1 and B likes item 2, A is more likely to like item 2. Content-based filtering is based on the idea that if user A likes item 1 and item 1 is similar to item 2, then A is more likely to like item 2. Hybrid methods combine the two above techniques to make the recommendations.
The main goal of a recommender system is to keep users engaged, simplify decision-making, and stimulate demand by populating products or content. In other words, the aim is to improve the user experience and increase sales or engagement.
Content-based filtering
Content-based filtering is a method of recommending items based on their attributes or characteristics. This approach uses the characteristics or features of an item to identify similar items that a user might also be interested in. For example, in a movie recommendation system, the attributes of a movie such as its genre, director, and actors can be used to recommend similar movies to a user who has watched a particular movie.
The main idea behind content-based filtering is that if a user likes an item, they will also like similar items. By analyzing the attributes of an item, the system can identify similar items and recommend them to the user. This approach is useful when there is a lot of information about the recommended items, such as music, movie, or book recommendation systems.

Collaborative filtering
Collaborative filtering is a method of recommending items based on the behavior and preferences of users. This approach generates recommendations by analyzing the behavior and preferences of users who are similar to the user for whom the recommendations are being generated. For example, if two users have similar movie preferences, then a movie that one user likes is likely to be recommended to the other user.
The main idea behind collaborative filtering is that users who have similar tastes and preferences are likely to enjoy similar items. By analyzing the behavior and preferences of users, the system can identify users who have similar tastes and preferences and recommend items that they like. Collaborative filtering is useful when there is limited information available about the items being recommended, such as in e-commerce or social media platforms.

For instance, if two users have similar preferences in books, the system will suggest books that one user likes to the other. In this example, let’s say User X and Y both enjoy George Orwell’s 1984, Aldous Huxley’s Brave New World, and John Steinbeck’s Of Mice and Men. But, User X also likes Jack Kerouac’s On the Road, while User Y likes Huxley’s book. Collaborative filtering would suggest that User X might like Kerouac’s book, and User Y might enjoy Huxley’s book. In reality, these systems analyze the interactions of millions of users to make accurate recommendations.
Collaborative filtering techniques can be categorized as memory-based and model-based.
Memory-Based
The memory-based approach for collaborative filtering is based on the idea that similar users will have similar preferences. It uses past data to predict future preferences by finding similar users or “neighbors” who share the same preferences. This method is often referred to as neighborhood-based collaborative filtering.
It’s a relatively simple method to implement and is known for its effectiveness. However, it can be limited in the variety of recommendations it can provide. It’s not well-suited for real-time recommendations or those that are less popular among users.
There are two types of memory-based collaborative filtering: item-item and user-user. Item-item CF compares items and user-user CF compares users.
User-user collaborative filtering, as the name suggests, is a method where the recommendations are generated by identifying similar users to the active user. It looks for users who have similar preferences and rating patterns to the active user and then recommends items that these similar users have liked in the past. This method is effective when the dataset is large and has a lot of users who have similar preferences. However, it can be computationally expensive as it requires similarity calculations between all pairs of users. Additionally, it also suffers from the “cold start” problem, where it’s hard to make recommendations for new users as they have not yet provided enough data for the system to establish their preferences.
Item-item collaborative filtering, on the other hand, compares how similar different items are to each other based on how users have rated them. In this approach, the system finds items that are similar to the ones the user has previously rated highly and recommends those similar items. This technique is particularly useful for recommending new items to users, as it doesn’t rely on the user’s past behavior and can discover hidden patterns in the data. However, it may not be as personalized as user-user collaborative filtering.
Model-Based
Model-based collaborative filtering, on the other hand, uses algorithms to create a model of user preferences and generate predictions. These models can be based on various techniques such as matrix factorization and clustering. They are more computationally intensive but also more accurate and scalable. They can handle the sparsity problem better and can be used to make personalized recommendations.
Hybrid filtering
Hybrid filtering is a combination of two or more methods such as content-based filtering, collaborative filtering, and demographic filtering. It uses multiple models to improve the accuracy and robustness of the recommendation system. This approach can be used when there is a combination of both user behavior data and item data available.
These methods are used to make recommendations to users by using their browsing history, purchase history, and other data. These systems are designed to keep users engaged, simplify decision-making, and ultimately stimulate demand. With the help of recommendation systems, users can discover new products and content, which in turn helps businesses increase sales and improve customer satisfaction.
My approach
I first filtered the data by considering only those users who have rated more than 200 books and only those books that have received more than 50 ratings.
- This step helped in reducing the noise and sparsity in the data by focusing on users and books that have a significant number of ratings.
- Next, calculated the similarity scores between the books using the Euclidean distance similarity measure.
- This approach calculates the distance between the ratings of two books, which helps in identifying the books that are similar in terms of their ratings. Finally, based on the similarity scores, generated recommendations for a selected book. By considering the books with the highest similarity scores to the selected book, were able to recommend other books that users with similar tastes might also enjoy.
def recommender(book_name):
if book_name not in table.index:
st.write("This book is not in our list, please try again.")
return None
else:
index = table.index.get_loc(book_name)
similar_items = np.argsort(similarity_scores[index])[-6:][::-1]
similar_book_titles = table.index[similar_items]
similar_books = books[books['Book-Title'].isin(similar_book_titles)]
return similar_books
The function ‘recommender’ takes in a single parameter ‘book_name’ which is the name of the book for which the user wants to get similar recommendations. First, the function checks if the input book name is present in the ‘table’ (which is assumed to be a dataframe containing book information) using the .index method. If the input book name is not found in the ‘table’, it returns an error message “This book is not in our list, please try again.” and the function ends.
- If the input book name is found in the ‘table’, the function then proceeds to find similar books using the following steps:
- It gets the index location of the input book in the ‘table’ using the .index.get_loc() method.
- It uses the numpy function np.argsort() to sort the similarity scores of the input book and select the top 6 similar items (based on their index positions in the ‘table’).
- It then gets the titles of the similar books using the .index[] method on the ‘table’ dataframe.
- It filters the ‘books’ dataframe (which is assumed to contain all book information) to select only the similar books found in the previous step.
- Finally, it returns the filtered ‘similar_books’ dataframe containing the similar book recommendations.

The complete code is uploaded on GitHub: